《编译原理 第二版》札记
这本编译原理的版本是机械工业出版社翻译的“龙书”第二版。
第一章
一个程序可以运行之前,它首先需要被翻译成一种能够被计算机执行的形式。 完成这项翻译工作的软件系统称为编译器(Compiler)。
研究编译器的编写将涉及程序设计语言、计算机体系架构、形式语言理论、算法和软件工程。
Java 语言处理器结合了编译和解释过程。一个 Java 程序首先被编译成一个称为字节码(bytecode)的中间表示形式,然后由一个虚拟机对得到的字节码加以解释执行。

1、词法分析
专业术语:
- 符号表:symbol table
- 词法分析:lexical analysis
- 词素:lexeme
- 词法单元:token。
词法单元的形式为
<token-name, attribute-value>。第一个分量 token-name
是一个由语法分析步骤使用的抽象符号,而第二个分量 attribute-value
指向符号表中关于这个词法单元的条目。
针对词法分析进行举例说明:
假设一个源程序包含如下的赋值语句
position = initial + rate * 60
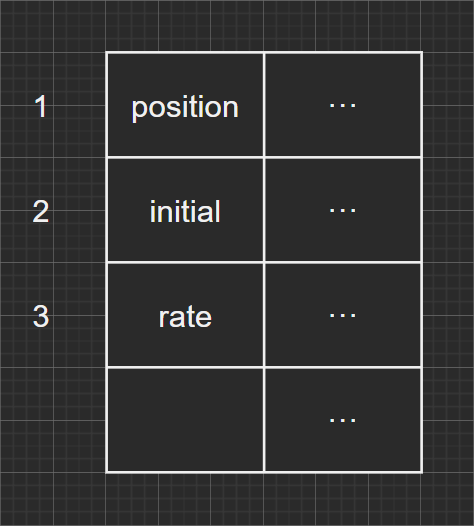
1) position 是一个词素,被映射成词法单元
<id, 1>,其中 id 是标识符(identifier)的抽象符号,而
1 指向符号表中 position
对应的条目。一个标识符对应的符号表条目存放该标识符有关的信息,比如它的名字和类型。
2)赋值符号 = 是一个词素,被映射成词法单元
<=>。
3)initial 是一个词素,被映射成词法单元
<id, 2>。
4)+ 是一个词素,被映射成词法单元 <+>。
5)rate 是一个词素,被映射成词法单元 <id, 3>。
6)* 是一个词素,被映射成词法单元 <*>。
7)60 是一个词素,被映射成词法单元 <60>。
最后,上面的赋值语句被表示成如下的词法单元序列:
<id, 1> <=> <id, 2> <+> <id, 3> <*> <60>
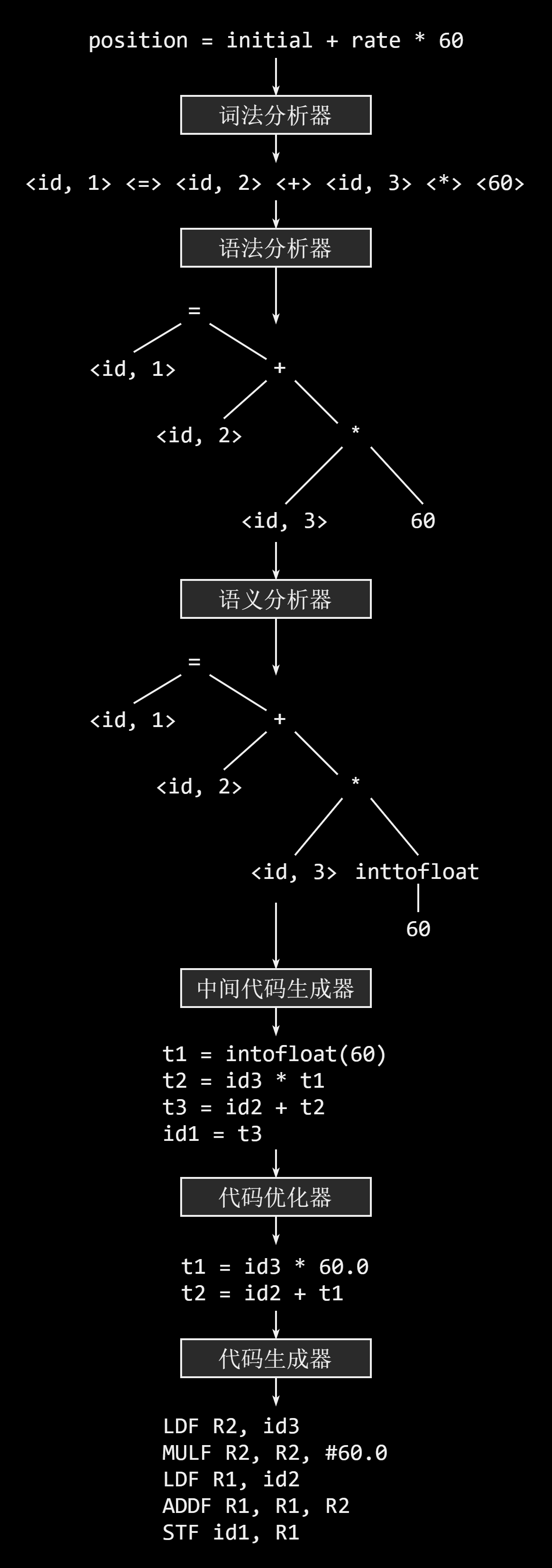
上面这个赋值语句的翻译,用举例的方式很好地解释了编译器编译语句的过程,让人可以对编译过程有一个初步的把握。
2、语法分析
专业术语:
- 语法分析:syntax analysis
语法分析器使用由词法分析器生成的各个词法单元的第一个分量来创建树形的中间表示。
一个常用的语法是语法树。
3、杂记
符号表数据结构为每个变量名字创建了一个记录条目。记录的字段就是名字的各个属性。这个数据结构应该允许编译器迅速查找到每个名字的记录,并向记录中快速存放和获取记录中的数据。(P6)
在一个特定的实现中,多个步骤的活动可以被组合成一趟(pass)。(P6)
1.5
何为类型检查?
举例,运算被作用于错误类型的对象上,或者传递给一个过程(procedure)的参数和该过程的范型(signature)不匹配。
按:这里的范型(signature)应该翻译成签名才会,这样才和函数的“签名”对得上。
何为边界检查?
举例,C 语言的数组需要进行边界检查,否则如果超出边界,可能会造成缓冲区溢出的问题。
何为内存管理工具?
举例,垃圾收集机制就是这样一个工具。内存管理需要解决诸如内存泄漏这样的内存泄露的问题。
1.6
何为静态和动态的区别?
主要有两个方面。
一个是策略。
- 一个语言使用的策略支持编译器静态决定某个问题,或者这个问题可以在编译时刻决定 ==> 静态策略。
- 只允许在运行程序的时候做出决定,或者需要在运行时刻做出决定 ==> 动态策略。
另一个是作用域。
- 静态作用域:仅通过阅读程序就可以确定一个声明的作用域。或者说,词法作用域。
- 动态作用域:上面的情况的例外。
环境和状态?
- 环境:是从一个从名字到存储位置的映射。
- 状态:是一个从内存位置到它们的值的映射。
局部的 i 通常被赋予一个运行时刻栈中的位置。
按:函数中的变量一般会被放入栈中,这一点和以前的知识是吻合的。
C 语言的声明必须先于使用。
静态绑定和动态绑定的使用频次?
一般来说,名字到位置的绑定,位置到值的绑定都是动态的。但是,它们都有例外。
名字、标识符和变量的区分?
标识符(identifier)是一个字符串。它用来指向(标记)一个实体。
所有标识符都是名字,但并不是所有的名字都是标识符,比如,x.y
是名字,但不是标识符。
变量指向存储中的某个特定的位置。同一个标识符被多次声明是常见的事情,每一个这样的声明引入一个新的变量。